国際航業と理化学研究所、東京大学、筑波大学の共同研究グループは、ドローン撮影画像から土砂災害を専門家レベルで分析するマルチモーダルAIシステムを開発した。
限られた専門家リソースを効率化し、災害対応時の迅速かつ安全なリスク評価を可能にする新技術となる。
気候変動により世界中で自然災害の発生頻度が高まる中、災害発生時の被害範囲や原因、追加リスクの迅速な評価は命を救い、二次災害防止に不可欠である。
高精度デジタルカメラや監視カメラネットワークの普及により災害地域の画像データ収集は飛躍的に向上したものの、現状では高度な判断や予測ができるのは十分な知識と経験を持つ専門家のみに限られている。
広範囲に及ぶ大規模災害では限られた数の専門家による即時意思決定は困難であり、複数の責任を担う専門家の効率的配置も課題となっていた。
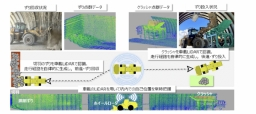
研究グループは過去の土砂災害現場画像を専門家に提示し、観察や分析を音声記録してテキストに変換した。
 (画像:地すべり災害の空撮画像から専門家レベルの分析を行うマルチモーダルAIシステム 活用イメージ)
(画像:地すべり災害の空撮画像から専門家レベルの分析を行うマルチモーダルAIシステム 活用イメージ)
これらのデータを「災害タイプ」「原因」「観察事項」「将来リスク」という標準的な構造に整理し、大規模言語モデルが効果的に学習できる形式に変換している。
開発したAIは「土砂災害の種類、原因、観察事項、将来リスクを説明してください」という固定指示プロンプトと災害画像を与えると、土砂災害現場の分析結果を生成する仕組みとなっている。
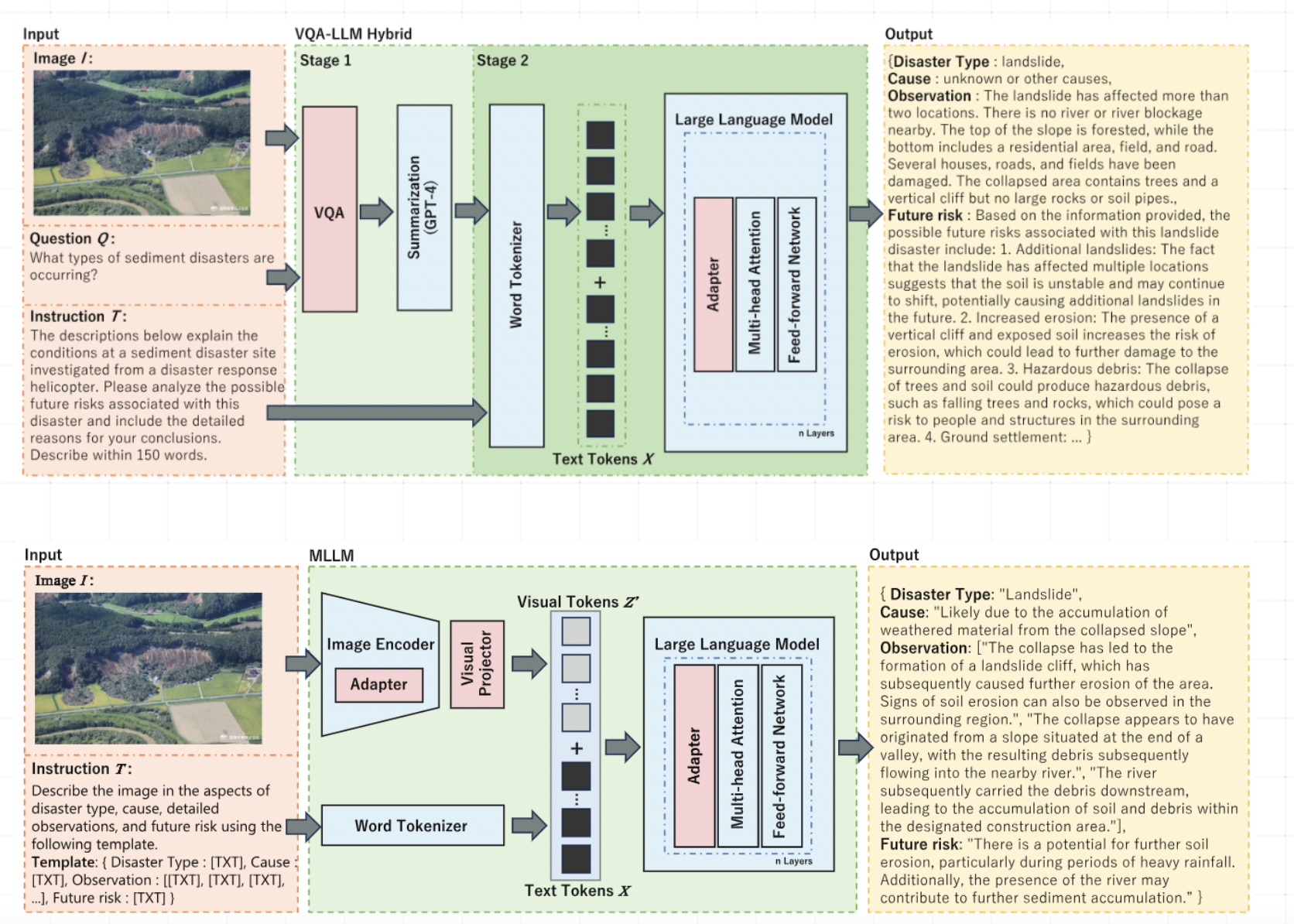 (画像:開発した2つのモデル)
(画像:開発した2つのモデル)
実際の災害画像に対してAIは災害タイプを正しく「Landslide」と識別し、原因を「人為的活動と自然侵食」と推測した。
観察事項では「細長い山岳地域内の急斜面」「露出した岩石」などの特徴を正確に捉え、将来リスクも「さらなる斜面崩壊と侵食の可能性」と妥当な予測を行っている。
 (画像:開発したAIによる土砂災害画像の判読結果)
(画像:開発したAIによる土砂災害画像の判読結果)
システムは画像から情報を抽出する視覚的質問応答モデルと大規模言語モデルを組み合わせたVQA-LLMハイブリッドと、画像と指示テキストを同時処理するマルチモーダル大規模言語モデルの2つのアプローチで開発された。
日本各地の土砂災害現場画像68枚をデータ拡張により136サンプルに増やして訓練し、従来のテキスト類似性指標に加え、大規模言語モデルによる意味的評価と専門家による評価も実施している。
参考・画像元:国際航業プレスリリースより
限られた専門家リソースを効率化し、災害対応時の迅速かつ安全なリスク評価を可能にする新技術となる。
専門家音声データを構造化して大規模言語モデルで学習
気候変動により世界中で自然災害の発生頻度が高まる中、災害発生時の被害範囲や原因、追加リスクの迅速な評価は命を救い、二次災害防止に不可欠である。
高精度デジタルカメラや監視カメラネットワークの普及により災害地域の画像データ収集は飛躍的に向上したものの、現状では高度な判断や予測ができるのは十分な知識と経験を持つ専門家のみに限られている。
広範囲に及ぶ大規模災害では限られた数の専門家による即時意思決定は困難であり、複数の責任を担う専門家の効率的配置も課題となっていた。
研究グループは過去の土砂災害現場画像を専門家に提示し、観察や分析を音声記録してテキストに変換した。
(画像:地すべり災害の空撮画像から専門家レベルの分析を行うマルチモーダルAIシステム 活用イメージ)これらのデータを「災害タイプ」「原因」「観察事項」「将来リスク」という標準的な構造に整理し、大規模言語モデルが効果的に学習できる形式に変換している。
開発したAIは「土砂災害の種類、原因、観察事項、将来リスクを説明してください」という固定指示プロンプトと災害画像を与えると、土砂災害現場の分析結果を生成する仕組みとなっている。
(画像:開発した2つのモデル)実際の災害画像に対してAIは災害タイプを正しく「Landslide」と識別し、原因を「人為的活動と自然侵食」と推測した。
観察事項では「細長い山岳地域内の急斜面」「露出した岩石」などの特徴を正確に捉え、将来リスクも「さらなる斜面崩壊と侵食の可能性」と妥当な予測を行っている。
(画像:開発したAIによる土砂災害画像の判読結果)システムは画像から情報を抽出する視覚的質問応答モデルと大規模言語モデルを組み合わせたVQA-LLMハイブリッドと、画像と指示テキストを同時処理するマルチモーダル大規模言語モデルの2つのアプローチで開発された。
日本各地の土砂災害現場画像68枚をデータ拡張により136サンプルに増やして訓練し、従来のテキスト類似性指標に加え、大規模言語モデルによる意味的評価と専門家による評価も実施している。
参考・画像元:国際航業プレスリリースより
WRITTEN by



建設土木のICT活用など、
デジコンからの最新情報をメールでお届けします