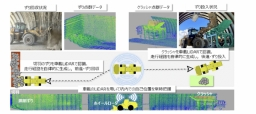
NTT東日本は2025年10月より、通信建設現場の安全性と業務効率の向上を目指して、視覚と言語を融合したマルチモーダル生成AI技術を活用した業界特化型VLMの研究開発を開始すると発表した。
同社はこれまで、通信建設現場の安全管理業務に物体検知AIを活用した危険作業検知AIを導入し、約5000台のネットワークカメラを運用することで、不安全行動の検知や遠隔見守りを実現してきた。
90パーセント以上のAI判定の精度と約70パーセントの稼働削減を達成し、業務効率の向上とリスクの低減に取り組んできた。
しかし、従来のAIモデルでは、複雑な現場状況の文脈理解や、作業内容に応じた柔軟な判断が難しいという課題が残っていた。
本研究では、画像とテキストの両方を理解できるVLMであるVision-Language Modelを活用し、これまで困難だった現場の状況説明や作業指示の自動生成を可能にすることで、安全確認の精度向上を高め、業務プロセスの高度化を図る。
作業時間の短縮や確認精度の向上により、安全管理業務の効率を従来比で約30パーセント向上させることを目指す。

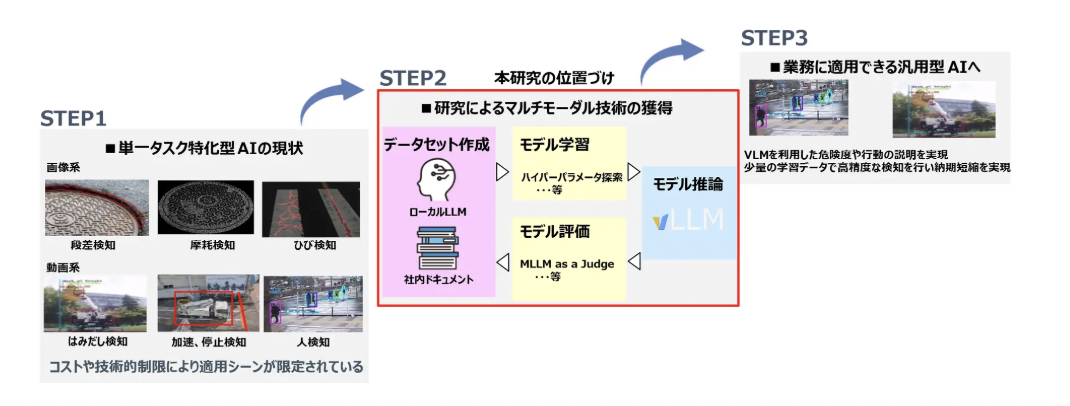
取組概要として、まず合成データ生成による高品質データセット構築に取り組む。
同社は通信建設現場での約5年間にわたるAIの屋外運用により、少量のデータでも多様性のある教師データを選定することで高精度なモデルを構築するノウハウを獲得している。
本研究では、社内業務知識と画像情報を組み合わせたVQA形式のデータセット作成に取り組む。
VQAはVisual Question Answeringの略で、LLMであるLarge Language Modelによる合成データ生成手法を活用して高品質なデータセットを効率的に構築する予定である。
次に、VLMのファインチューニングによる最適化を行う。
マルチモーダルAIであるVLMをファインチューニングすることで、通信業界に特化したVLMを構築する。
学習手法は、フルパラメータやLoRAであるLow-Rank Adaptationという効率的なファインチューニング手法を比較検討し、約720億パラメータ級のモデルの学習と評価に取り組む。
また、現在の危険作業検知AIは優先度の高い8種類のみに対応している物体検知AIであるため、不安全な行動やヘルメットをはじめ装備品の未着用の検知など、より複雑な状況に対応していくことで、約16種類に適応領域の拡大を目指す。
さらに、マルチモーダルAIにおける評価手法の確立に取り組む。
独自の業界や業務におけるマルチモーダルAIの評価事例は少ないため、LLMによる自動評価手法であるLLM as a JudgeやROUGEなどの指標をマルチモーダル評価に拡張していく。
安全管理の専門知識をもとにした独自の評価データセットを作成し、評価手法を確立することで精度を検証予定である。
今後の予定として、2025年度中に研究を完了し、その後、見守りや安全指導を行う現場での実用化に向け、現場での有効性を検証していく。
約5000台のネットワークカメラ運用実績を基盤に高度化
同社はこれまで、通信建設現場の安全管理業務に物体検知AIを活用した危険作業検知AIを導入し、約5000台のネットワークカメラを運用することで、不安全行動の検知や遠隔見守りを実現してきた。
90パーセント以上のAI判定の精度と約70パーセントの稼働削減を達成し、業務効率の向上とリスクの低減に取り組んできた。
しかし、従来のAIモデルでは、複雑な現場状況の文脈理解や、作業内容に応じた柔軟な判断が難しいという課題が残っていた。
本研究では、画像とテキストの両方を理解できるVLMであるVision-Language Modelを活用し、これまで困難だった現場の状況説明や作業指示の自動生成を可能にすることで、安全確認の精度向上を高め、業務プロセスの高度化を図る。
作業時間の短縮や確認精度の向上により、安全管理業務の効率を従来比で約30パーセント向上させることを目指す。
取組概要として、まず合成データ生成による高品質データセット構築に取り組む。
同社は通信建設現場での約5年間にわたるAIの屋外運用により、少量のデータでも多様性のある教師データを選定することで高精度なモデルを構築するノウハウを獲得している。
本研究では、社内業務知識と画像情報を組み合わせたVQA形式のデータセット作成に取り組む。
VQAはVisual Question Answeringの略で、LLMであるLarge Language Modelによる合成データ生成手法を活用して高品質なデータセットを効率的に構築する予定である。
次に、VLMのファインチューニングによる最適化を行う。
マルチモーダルAIであるVLMをファインチューニングすることで、通信業界に特化したVLMを構築する。
学習手法は、フルパラメータやLoRAであるLow-Rank Adaptationという効率的なファインチューニング手法を比較検討し、約720億パラメータ級のモデルの学習と評価に取り組む。
また、現在の危険作業検知AIは優先度の高い8種類のみに対応している物体検知AIであるため、不安全な行動やヘルメットをはじめ装備品の未着用の検知など、より複雑な状況に対応していくことで、約16種類に適応領域の拡大を目指す。
さらに、マルチモーダルAIにおける評価手法の確立に取り組む。
独自の業界や業務におけるマルチモーダルAIの評価事例は少ないため、LLMによる自動評価手法であるLLM as a JudgeやROUGEなどの指標をマルチモーダル評価に拡張していく。
安全管理の専門知識をもとにした独自の評価データセットを作成し、評価手法を確立することで精度を検証予定である。
今後の予定として、2025年度中に研究を完了し、その後、見守りや安全指導を行う現場での実用化に向け、現場での有効性を検証していく。
WRITTEN by



建設土木のICT活用など、
デジコンからの最新情報をメールでお届けします