

およそ10年前の2012年、Googleがディープラーニングにより猫を識別したというニュースは世界中を驚かせた。
以来、ディープラーニングはさまざまな分野で実用化されており、AI・人工知能の世界を飛躍的に広げている。
人間の脳の動きを模倣したモデルでどのように情報を処理していくかを理解すると、なぜディープラーニングがAIの中心的な技術なのかが見えてくる。
「ディープラーニング」という言葉は最近ではよく使われるようになり、AIの代名詞のように捉えられている。
1956年にダートマス会議で「AI」という言葉が誕生して以降、AIの研究は進められてきたものの、幾度となく冬の時代を迎え、実用化されずにいた。
ようやく2000年代に入ってさまざまな分野で活用されるようになったのは、ディープラーニング技術の誕生が大きい。
ディープラーニングという言葉が使われるようになったのは2000年代の後半だが、その原型ともいえるニューラルネットワークが誕生したのは、1943年のことだ。
人間の脳は、神経細胞とそのネットワークで構成されているため、この動きを模倣することで高度な情報処理ができるのではないかと考え、数式モデルが生み出された。
このようにディープラーニングの歴史は長いのに、なぜ2000年代になるまでクローズアップされなかったかというと、当時のコンピューター資源では計算するのに膨大な時間がかかるため現実的でなかったからである。
しかし2012年にGoogleがディープラーニングによって「人が教えなくても、自発的に猫を認識した」と発表し、世界に衝撃を与えた。
動画から1000万枚の画像をディープラーニングで学習させたところ、人間が何も教えなくても猫の姿を識別することができたという。
テキストデータでない画像のデータを解析するには、単純だが膨大な計算が必要となる。
2010年代にGPUと呼ばれる単純な計算を並行処理で行うことに長けている演算用チップが登場して、ディープラーニングが現実的なものとなった。以降、ディープラーニングはAIのメインストリームの技術となっている。
最近ではディープラーニングの技術を活用することが多いため、「AI=ディープラーニング」と捉える人も多いかもしれない。
同じように「AI=機械学習」と捉える人も多いが、ディープラーニングと機械学習の違いはどこにあるのだろうか。

一言でいえば、ディープラーニングは機械学習の一種だ。そしてAIはもっと広範囲で、どこまでがAIの範疇かということを定義するのは難しい。
しかし、大まかにAIを分類するならば、2つのパターンに分かれる。専門的な分野に限定して機能する「特化型AI」と人間と同等の知能を持たせようとする「汎用型AI」だ。
現在さまざまな分野で実用化されているのが「特化型AI」である。
特化型AIは、人間がルールを定義するか、データから学習するかの2パターンあり、ディープラーニングも含めて機械学習は後者にあたる。
人間がルールを定義すると、現実的でないほどの労力がかかると同時に、精度が人間の能力に左右されてしまう。一方でルールをデータからAIが自律的に読み取ることができれば、精度が高くなり、人間が気付かない価値を生み出すこともできる。
機械学習が評価されているのはこのような点からだ。
機械学習は統計モデルがベースとなっている。つまり大量のデータから特徴を導き出し、確率で答えを出すのが基本的な機能だと押さえておこう。
ディープラーニングも同様だが、他のモデルと違い、人間の脳の動きを取り入れたことに特徴がある。
ディープラーニングの原型は「ニューラルネットワーク(NN)」と呼ばれるもので、1943年に人間の脳を模倣したモデルが提唱されたことから始まった。
伝統的な統計モデルではあるが、複雑な分布を持つデータ群に適用できないという問題があり、日の目を見ない時代が続いた。
しかしディープラーニングの登場により、AIのメインストリームの技術として脚光を浴びるようになる。
ディープラーニングは、人間の脳の仕組みを情報処理に生かすという発想から生まれたが、人間の脳全体を模倣しているわけではない。
あくまでも脳の神経細胞とそのつながり(シナプス)の動きをモデルとしたもので、脳をつかさどるすべての器官の動きを表しているわけではない。
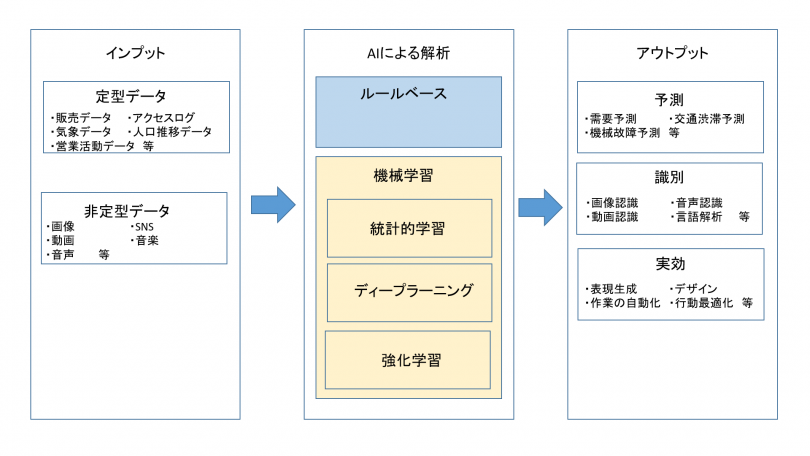
ディープラーニングはどのような仕組みなのかを見ていこう。まず原型となるニューラルネットワークは、「入力層」「隠れ層」「出力層」で構成されている。
各層には複数の神経細胞(ノード)がある。
隠れ層は、入力層からのインプットを判断した結果を出力層に渡す。ただし、入力層からのインプットや隠れ層からの結果は等しく評価されるわけではなく、重みづけがされている。
人間の脳でも神経細胞をつなぐシナプスには強いものと弱いものがある。重みづけはシナプスの強弱を表現している。
たとえば、画像から猫を識別するためには、最初に猫の輪郭を識別する必要がある。猫を人間や犬やネズミと区別するには、輪郭を見る。
まず猫であれば「1. 耳が2つあること」が条件のひとつである。
もちろんAIには「耳」という概念はないが、1のような突起の輪郭があり、同じような突起の輪郭が平行線上の場所にもうひとつ存在したら、耳の可能性が高い(人間の耳は頭頂より上に出ることはない)。

そして2のように輪郭が丸いカーブを描いていたら猫の可能性が高い(犬ならもっとシャープな輪郭になる)。
ディープラーニングは通常こうした検証を画素単位で行う。
私たちが通常扱っている画像は、小さなピクセル(ドット)の集合体だ。1ピクセルはRGBのカラーで600×450画素数の画像であれば、600×450×3(RGB値)個のひとつひとつが入力層になる。
従来の機械学習であれば、「1. 耳が頭頂に2つある」「2. 顔の輪郭が丸い」といった特徴量を人間が一つひとつ定義していたが、ディープラーニングは自動で算出できる。
しかし、猫と判断するのは輪郭だけではない。
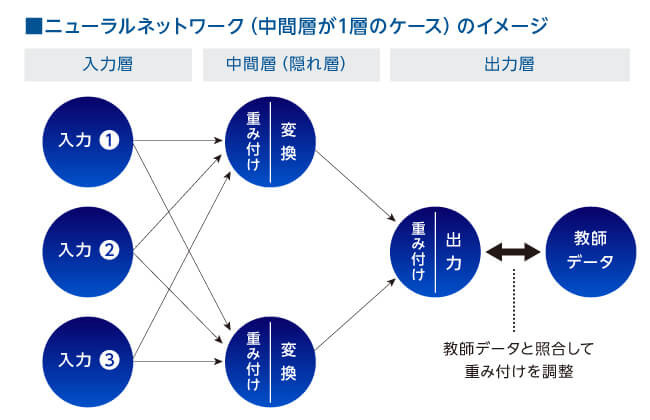
輪郭がベースにありその上で表面の毛や目や鼻があるか、どんな形をしているかといった細部も判断材料となる。中間層において、抽象度の高い層から具体性を持つ層まで多段階(ディープ)で判断する必要がある。
そこでディープラーニングの登場だ。隠れ層が多層になることで、画像等の解析が行えるようなる。
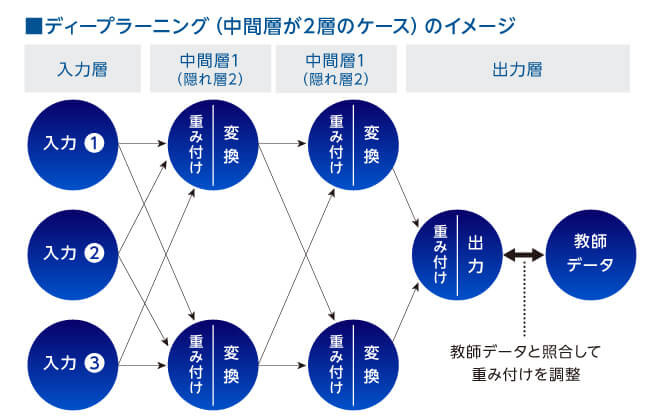
しかし、画素の一つひとつが等しく重要であるわけではない。
例えば背景の背景などは猫の識別に必要がない。そのため、判定には重みづけが必要だが、一般的には、猫の正解画像を学習して、重みづけを自動で調整している。
隠れ層の階層をさかのぼって自動で調整しているため、判別基準は人間からはブラックボックスとなっており、説明することができない。
ディープラーニングの仕組みの何が良いかというと、画像や音声など、非テキストベースのデータを圧倒的な精度で解析することができるからだ。
2010年代には、スマートフォンが普及し、誰でも画像や音声、動画を扱うようになった。このようなデータを解析することは、今までにない価値を生み出すことになる。
例えばレントゲン画像を見て初期の癌の可能性を検出したり、本編の映画を学習して予告を自動生成したりすることもできるようになった。

画像や音声、動画が高い精度で解析できることで、AIの価値が飛躍的に増大したと言える。音声認識した結果からテキストを生成するなど、複数の処理を組み合わせて高度な活用をすることもできる。
ディープラーニングの中にもさまざまな種類があり、用途に応じて使い分ける。代表的なものを紹介しよう。
画像認識の代表的な手法。画像の特徴を抜き出し、情報を効率的に圧縮してから最終的に分類を行うのが特徴だ。
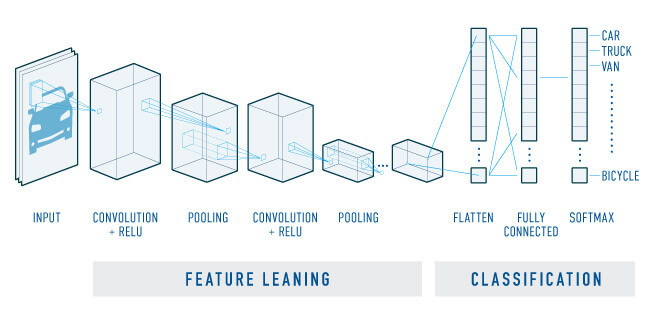
まず畳み込み層で特徴量の検出が行われる。特徴量の情報はプーリング(間引き)層へ送られ、特徴量を維持したまま、情報を圧縮する。これを繰り返し、後半はニューラルネットワークと同じ処理(分類)を行う。
先ほど猫の識別で見た通り、画像は膨大な情報を解析しなければならないため、膨大な計算量となる。
CNNによって情報を圧縮しながら解析ができるので、コンピューターのリソースが少なくても動作させることができる。
CNNの場合は、画素をひとつのノードとして一つずつ並列に判定していくので、例えば音声のような時系列のデータについて、過去のノードの判定結果をたことができない。
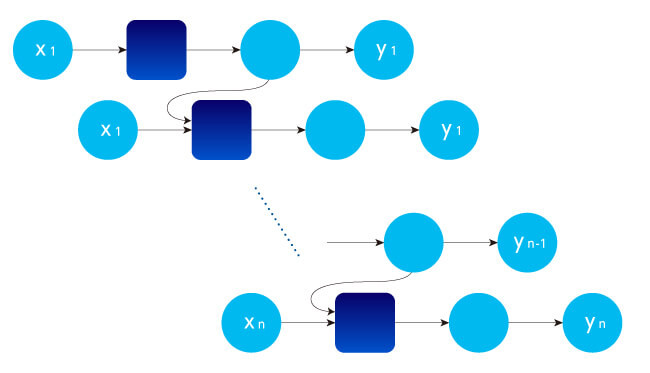
そこでRNNでは、判定した結果を上位の層だけでなく、下位の層のインプットにするという再帰的な構造を持っている。
ディープラーニングは隠れ層の階層が深いと、より精緻な判定ができると思われがちだが、初期のディープラーニングは、階層を深くすると精度が上がらないという問題があった。
ディープラーニングの学習では、アウトプットを正解データと照らし合わせ、誤差を階層をさかのぼって伝えていくが、階層を遡るほど誤差の情報が欠落してしまうため、正解データと照らし合わせても精度が上がらなくなる。
また、学習したデータに適合しすぎる(過学習)と、いざ新しいデータで評価すると正解率が落ちてしまうという問題があった。
そこで、オートエンコーダ―で入力データをあらかじめ抽象化して(事前学習)、そのデータを入力データとするという対応を行っていた。
現在はディープラーニングのアルゴリズムが改良されて、事前学習は不要になったが、画像のノイズ除去や、ノイズ検知に使われている。
生成モデルの一種。ジェネレーター(生成器)と、ディスクリミネーター(識別器)の2つのネットワークで構成されている。
例えばジェネレーターがあるパラメーターを受け取って生成した有名人の画像をディスクリミネーターが本物か偽物か判定する。ジェネレーターが偽物の画像を本物に限りなく近づけていき、ディスクリミネーターはどんなに似ていても偽物を判定する。
このように互いに精度を上げていくことで本物のような画像を生成することができるようになった。
例えば商品である洋服を着た実在しない人物の画像を大量に生成して、アパレルECの商品ページに表示すれば、閲覧した人は商品について具体的なイメージを持つことができる。
ディープラーニングの概要をまとめてみよう。
ディープラーニングは導入までの準備に労力がかかると思われるかもしれないが、クラウドやAPIを活用することで、簡単にディープラーニングの技術を活用できるようになった。
特にAIはビジネスに対して効果がでるかどうかは、やってみないとわからないという特徴がある。
最初はできるだけ小さく始めて、知見を蓄積していった先に、大きな価値が見えてくるだろう。
以来、ディープラーニングはさまざまな分野で実用化されており、AI・人工知能の世界を飛躍的に広げている。
人間の脳の動きを模倣したモデルでどのように情報を処理していくかを理解すると、なぜディープラーニングがAIの中心的な技術なのかが見えてくる。
ディープラーニング誕生の背景
「ディープラーニング」という言葉は最近ではよく使われるようになり、AIの代名詞のように捉えられている。
1956年にダートマス会議で「AI」という言葉が誕生して以降、AIの研究は進められてきたものの、幾度となく冬の時代を迎え、実用化されずにいた。
ようやく2000年代に入ってさまざまな分野で活用されるようになったのは、ディープラーニング技術の誕生が大きい。
ディープラーニングという言葉が使われるようになったのは2000年代の後半だが、その原型ともいえるニューラルネットワークが誕生したのは、1943年のことだ。
人間の脳は、神経細胞とそのネットワークで構成されているため、この動きを模倣することで高度な情報処理ができるのではないかと考え、数式モデルが生み出された。
このようにディープラーニングの歴史は長いのに、なぜ2000年代になるまでクローズアップされなかったかというと、当時のコンピューター資源では計算するのに膨大な時間がかかるため現実的でなかったからである。
しかし2012年にGoogleがディープラーニングによって「人が教えなくても、自発的に猫を認識した」と発表し、世界に衝撃を与えた。
動画から1000万枚の画像をディープラーニングで学習させたところ、人間が何も教えなくても猫の姿を識別することができたという。
テキストデータでない画像のデータを解析するには、単純だが膨大な計算が必要となる。
2010年代にGPUと呼ばれる単純な計算を並行処理で行うことに長けている演算用チップが登場して、ディープラーニングが現実的なものとなった。以降、ディープラーニングはAIのメインストリームの技術となっている。
ディープラーニングと機械学習の違いとは
最近ではディープラーニングの技術を活用することが多いため、「AI=ディープラーニング」と捉える人も多いかもしれない。
同じように「AI=機械学習」と捉える人も多いが、ディープラーニングと機械学習の違いはどこにあるのだろうか。
一言でいえば、ディープラーニングは機械学習の一種だ。そしてAIはもっと広範囲で、どこまでがAIの範疇かということを定義するのは難しい。
しかし、大まかにAIを分類するならば、2つのパターンに分かれる。専門的な分野に限定して機能する「特化型AI」と人間と同等の知能を持たせようとする「汎用型AI」だ。
現在さまざまな分野で実用化されているのが「特化型AI」である。
特化型AIは、人間がルールを定義するか、データから学習するかの2パターンあり、ディープラーニングも含めて機械学習は後者にあたる。
人間がルールを定義すると、現実的でないほどの労力がかかると同時に、精度が人間の能力に左右されてしまう。一方でルールをデータからAIが自律的に読み取ることができれば、精度が高くなり、人間が気付かない価値を生み出すこともできる。
機械学習が評価されているのはこのような点からだ。
機械学習は統計モデルがベースとなっている。つまり大量のデータから特徴を導き出し、確率で答えを出すのが基本的な機能だと押さえておこう。
ディープラーニングも同様だが、他のモデルと違い、人間の脳の動きを取り入れたことに特徴がある。
ディープラーニングの原型は「ニューラルネットワーク(NN)」と呼ばれるもので、1943年に人間の脳を模倣したモデルが提唱されたことから始まった。
伝統的な統計モデルではあるが、複雑な分布を持つデータ群に適用できないという問題があり、日の目を見ない時代が続いた。
しかしディープラーニングの登場により、AIのメインストリームの技術として脚光を浴びるようになる。
ディープラーニングの仕組み
ディープラーニングは、人間の脳の仕組みを情報処理に生かすという発想から生まれたが、人間の脳全体を模倣しているわけではない。
あくまでも脳の神経細胞とそのつながり(シナプス)の動きをモデルとしたもので、脳をつかさどるすべての器官の動きを表しているわけではない。
ディープラーニングはどのような仕組みなのかを見ていこう。まず原型となるニューラルネットワークは、「入力層」「隠れ層」「出力層」で構成されている。
各層には複数の神経細胞(ノード)がある。
隠れ層は、入力層からのインプットを判断した結果を出力層に渡す。ただし、入力層からのインプットや隠れ層からの結果は等しく評価されるわけではなく、重みづけがされている。
人間の脳でも神経細胞をつなぐシナプスには強いものと弱いものがある。重みづけはシナプスの強弱を表現している。
たとえば、画像から猫を識別するためには、最初に猫の輪郭を識別する必要がある。猫を人間や犬やネズミと区別するには、輪郭を見る。
まず猫であれば「1. 耳が2つあること」が条件のひとつである。
もちろんAIには「耳」という概念はないが、1のような突起の輪郭があり、同じような突起の輪郭が平行線上の場所にもうひとつ存在したら、耳の可能性が高い(人間の耳は頭頂より上に出ることはない)。
そして2のように輪郭が丸いカーブを描いていたら猫の可能性が高い(犬ならもっとシャープな輪郭になる)。
ディープラーニングは通常こうした検証を画素単位で行う。
私たちが通常扱っている画像は、小さなピクセル(ドット)の集合体だ。1ピクセルはRGBのカラーで600×450画素数の画像であれば、600×450×3(RGB値)個のひとつひとつが入力層になる。
従来の機械学習であれば、「1. 耳が頭頂に2つある」「2. 顔の輪郭が丸い」といった特徴量を人間が一つひとつ定義していたが、ディープラーニングは自動で算出できる。
しかし、猫と判断するのは輪郭だけではない。
輪郭がベースにありその上で表面の毛や目や鼻があるか、どんな形をしているかといった細部も判断材料となる。中間層において、抽象度の高い層から具体性を持つ層まで多段階(ディープ)で判断する必要がある。
そこでディープラーニングの登場だ。隠れ層が多層になることで、画像等の解析が行えるようなる。
しかし、画素の一つひとつが等しく重要であるわけではない。
例えば背景の背景などは猫の識別に必要がない。そのため、判定には重みづけが必要だが、一般的には、猫の正解画像を学習して、重みづけを自動で調整している。
隠れ層の階層をさかのぼって自動で調整しているため、判別基準は人間からはブラックボックスとなっており、説明することができない。
ディープラーニングの仕組みの何が良いかというと、画像や音声など、非テキストベースのデータを圧倒的な精度で解析することができるからだ。
2010年代には、スマートフォンが普及し、誰でも画像や音声、動画を扱うようになった。このようなデータを解析することは、今までにない価値を生み出すことになる。
例えばレントゲン画像を見て初期の癌の可能性を検出したり、本編の映画を学習して予告を自動生成したりすることもできるようになった。
画像や音声、動画が高い精度で解析できることで、AIの価値が飛躍的に増大したと言える。音声認識した結果からテキストを生成するなど、複数の処理を組み合わせて高度な活用をすることもできる。
ディープラーニングの種類
ディープラーニングの中にもさまざまな種類があり、用途に応じて使い分ける。代表的なものを紹介しよう。
畳み込みネットワーク(CNN)
画像認識の代表的な手法。画像の特徴を抜き出し、情報を効率的に圧縮してから最終的に分類を行うのが特徴だ。
まず畳み込み層で特徴量の検出が行われる。特徴量の情報はプーリング(間引き)層へ送られ、特徴量を維持したまま、情報を圧縮する。これを繰り返し、後半はニューラルネットワークと同じ処理(分類)を行う。
先ほど猫の識別で見た通り、画像は膨大な情報を解析しなければならないため、膨大な計算量となる。
CNNによって情報を圧縮しながら解析ができるので、コンピューターのリソースが少なくても動作させることができる。
再起型ニューラルネットワーク(RNN)
CNNの場合は、画素をひとつのノードとして一つずつ並列に判定していくので、例えば音声のような時系列のデータについて、過去のノードの判定結果をたことができない。
そこでRNNでは、判定した結果を上位の層だけでなく、下位の層のインプットにするという再帰的な構造を持っている。
オートエンコーダ
ディープラーニングは隠れ層の階層が深いと、より精緻な判定ができると思われがちだが、初期のディープラーニングは、階層を深くすると精度が上がらないという問題があった。
ディープラーニングの学習では、アウトプットを正解データと照らし合わせ、誤差を階層をさかのぼって伝えていくが、階層を遡るほど誤差の情報が欠落してしまうため、正解データと照らし合わせても精度が上がらなくなる。
また、学習したデータに適合しすぎる(過学習)と、いざ新しいデータで評価すると正解率が落ちてしまうという問題があった。
そこで、オートエンコーダ―で入力データをあらかじめ抽象化して(事前学習)、そのデータを入力データとするという対応を行っていた。
現在はディープラーニングのアルゴリズムが改良されて、事前学習は不要になったが、画像のノイズ除去や、ノイズ検知に使われている。
敵対的生成ネットワーク(GAN)
生成モデルの一種。ジェネレーター(生成器)と、ディスクリミネーター(識別器)の2つのネットワークで構成されている。
例えばジェネレーターがあるパラメーターを受け取って生成した有名人の画像をディスクリミネーターが本物か偽物か判定する。ジェネレーターが偽物の画像を本物に限りなく近づけていき、ディスクリミネーターはどんなに似ていても偽物を判定する。
このように互いに精度を上げていくことで本物のような画像を生成することができるようになった。
例えば商品である洋服を着た実在しない人物の画像を大量に生成して、アパレルECの商品ページに表示すれば、閲覧した人は商品について具体的なイメージを持つことができる。
ディープラーニングの活用法はしっかりと見極めて
ディープラーニングの概要をまとめてみよう。
ディープラーニングの概要
- ディープラーニングは機械学習の一種である
- 「入力層」「隠れ層」「出力層」に分かれており、隠れ層を多階層にすることで複雑な分布を持つデータの解析が可能となった
- 人間が特徴量を定義しなくても、自律的にデータを学習して判別できる
- 画像、動画、音声といった非テキストベースのデータを高い精度で解析できる
- ディープラーニングの中にも、さまざまなタイプがあり用途に合わせて適用できる
ディープラーニングは導入までの準備に労力がかかると思われるかもしれないが、クラウドやAPIを活用することで、簡単にディープラーニングの技術を活用できるようになった。
特にAIはビジネスに対して効果がでるかどうかは、やってみないとわからないという特徴がある。
最初はできるだけ小さく始めて、知見を蓄積していった先に、大きな価値が見えてくるだろう。
参考:
総務省|平成28年版 情報通信白書|人工知能(AI)研究の歴史https://www.soumu.go.jp/johotsusintokei/whitepaper/ja/h28/html/nc142120.html総務省 ICTスキル総合習得教材-[コース3]データ分析-3-5:人工知能と機械学習 | 総務省[PDF]https://www.soumu.go.jp/ict_skill/pdf/ict_skill_3_5.pdf
◎表・グラフ以外画像:Shutterstock
総務省|平成28年版 情報通信白書|人工知能(AI)研究の歴史https://www.soumu.go.jp/johotsusintokei/whitepaper/ja/h28/html/nc142120.html総務省 ICTスキル総合習得教材-[コース3]データ分析-3-5:人工知能と機械学習 | 総務省[PDF]https://www.soumu.go.jp/ict_skill/pdf/ict_skill_3_5.pdf
◎表・グラフ以外画像:Shutterstock
WRITTEN by
